everything是一款功能强大的文件搜索工具,正则表达式在其中的运用能极大提升搜索效率。以下从多个维度介绍everything正则查找技巧。
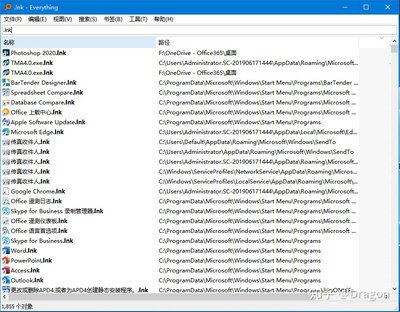
基本语法
正则表达式有其特定语法。例如,字符匹配方面,“.”可以匹配任意一个字符。比如搜索“t..t”,能找到“test”等包含四个字符且中间两个任意字符的文件或文件夹。“*”表示匹配前面字符零次或多次,像搜索“*.txt”,可找出所有txt文件。“+”则是匹配前面字符一次或多次,“?”匹配前面字符零次或一次。
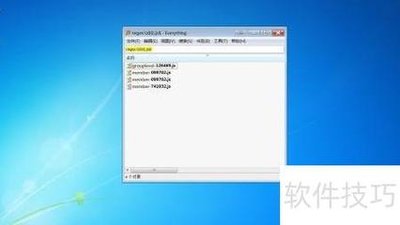
字符类
方括号用于定义字符类。[abc]表示匹配a、b、c中的任意一个字符。搜索“[abc].txt”,能定位文件名以a、b或c开头且后缀为txt的文件。而[!abc]表示除了a、b、c之外的任意字符。
量词
可精确控制匹配次数。{n}表示恰好匹配n次,{n,}表示至少匹配n次,{n,m}表示匹配n到m次。例如搜索“ab{2}c”,会找到包含“abbc”的文件;搜索“ab{2,4}c”,能找出“abbc”,“abbbc”,“abbbbc”相关文件。
位置匹配
“^”表示匹配字符串开头,“$”表示匹配字符串结尾。搜索“^test”可找出文件名开头为“test”的文件;搜索“test$”能定位文件名结尾是“test”的文件。
分组与引用
通过括号进行分组,如(abc),之后可通过
进行引用,n为分组序号。例如搜索“(abc).*⁄1”,能找到包含与前面括号内内容相同字符串的文件,即有两个连续相同的“abc”部分。
实战运用
在搜索大量文件时,正则表达式能快速定位所需。比如要查找所有包含特定字符串且文件名中包含数字的文件,可使用正则表达式“特定字符串.*⁄d”进行搜索。若要查找文件名中包含特定单词且在特定位置的文件,可利用位置匹配和字符匹配组合来构建正则表达式。
掌握everything正则查找技巧,能让我们在海量文件中迅速精准找到目标,大大提高工作和学习效率。